
Welcome to part eight of the interview series, where Speero’s CEO, Ben Labay, chats with experimentation leaders from top companies like Spotify, Vista, Hulu, AMEX, Booking.com, Disney, and others.
The goal is to explore how these companies structure and scale their experimentation efforts, particularly concerning the Center of Excellence (CoE) model.

You can find all the interviews and resources on this Miro board. Or just read/listen to any interview on the list:
- How to build the right CoE with the Right Tech, Process, and Contract, with Stewart Ehoff, head of growth platforms and product operations at RS Group.
- Three Key Steps to Launching CoE, with Melanie Kyrklund, global head of experimentation at Specsavers.
- CoE: Change Starts Everywhere, with Ruben de Boer, lead experimentation consultant at Online Dialogue.
- Why One Structure Doesn't Fit All Companies, with Rommil Santiago, founder of Experiment Nation and Sr. Director of Product Experimentation at Constant Contact.
- How CoE can work like a Charm in a Brand with 6K Employees, with Luis Trindade, Principal Product Manager of Experimentation at Farfetch.
- Hitting the JIRA Wall–Why Waterfall Fails Experimentation and What Works Instead, with Dan Layfield, director of product management at Diligent, ex-Uber.
- Centralized Teams Can Work Wonders in Small Businesses, with Kevin Anderson, Sr. Product Manager of Experimentation at Vista and the writer of the Experimental Mind newsletter.
- Backtest, Incentivise, and Watch Out for Variance, with Liam Furnam, data scientist at RealFi (ex-Booking, ex-Meta).
- Replacing CoE with an Experimentation Guild, with Tim Thijsse, CXO specialist at Online Plastics Group, Ex-Beerwulf (Heineken subsidiary).
- Get Your Head Out of the Sand, with Marty Cagan, writer of Inspired, Empowered, and Transformed, and partner at Silicon Valley Product Group.
In this interview, Ben sat with Liam Furnam, data scientist at RealFi, to talk about what his previous experience at Booking.com and Meta taught him about why backtesting is an excellent way to prove impact, why variance will make you centralize your experimentation efforts (instead of opening new departments every quarter), and a lot more.
Meta-project Management: Why You Should Backtest Everything
At Meta, Liam found an already developed experimentation structure based on project management: each pillar of business growth had their own experimentation team. Why? Different areas of the company have different needs, especially in big ones like Meta.
For example, the advertising side had its own group of experimentation specialists. “If you wanted to claim impact from your launch, you had to run an experiment.” Then a back test. This involved launching the feature 100%, then holding it back for 5% of users.
The experimentation team also carefully managed interactions between experiments. This meant teams couldn't just run experiments whenever they pleased; they had to book "test slots."
The experimentation team managed these slots, helped arrange them, and even innovated in the experimentation space to find techniques that could reduce the number of slots required, as the limitation on slots was a significant issue. “It was simply too complex for individual product teams to manage this themselves.”
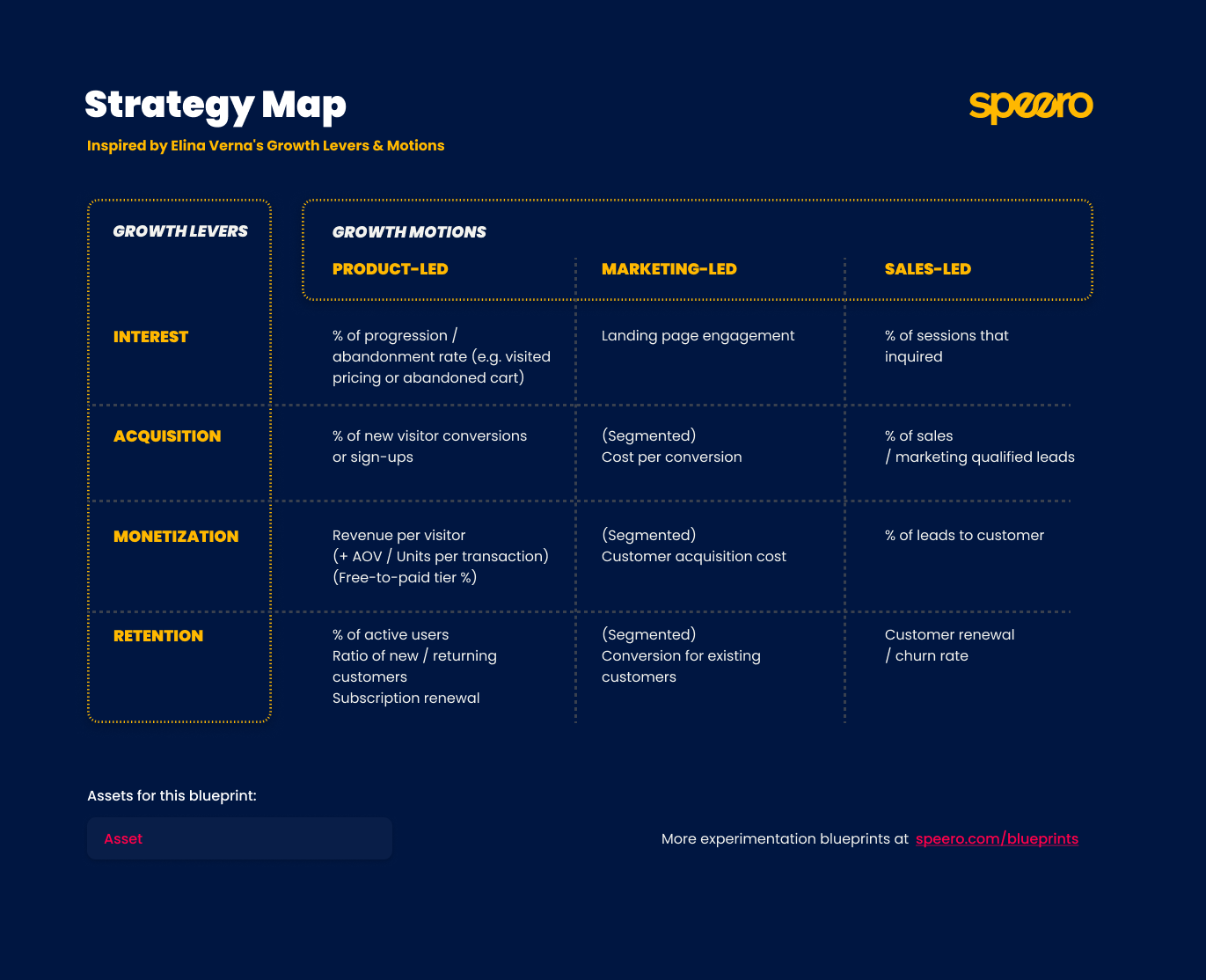
If you’re wondering how to orient your experimentation, the Strategy Maps blueprint can help you. It let’s you understand if your experimentation is focused on:
- Brand, performance, or product marketing
- Acquisition, Monetization, Retention
- Sales-led, marketing-led, or product-led.
Booking(com): Variance Begets Centralization
When Liam first joined, Booking.com’s structure mirrored Meta's in some ways. Customer-facing, partner-facing (hotel owners), and customer service-facing areas each had their own distinct experimentation teams.
This setup was again driven by the highly specific needs and requirements of each area. For example, in hotel-facing experimentation, where Liam worked, they dealt with immense variance, from large hotel chains like Hilton to individuals renting out their houses during the weekend. This often lead to underpowered tests.
However, as Booking.com scaled into offering more services like flights and car rentals, the organization realized this decentralized model wasn't sustainable. The idea of spinning up a new experimentation team for every new product offering was not scalable.
“Okay, we can't have an experimentation team for flights and an experimentation team for car rentals. If every time there's a new product offering, we have to spin up a new experimentation team, that's just not scalable.”
So, all those separate experimentation teams were centralized into one large experimentation department. While this centralization offered scalability and improved collaboration among experimentation teams, it presented a new challenge: the risk of losing touch with the individual customer needs.
Liam described this as "sitting in your ivory tower." To address this, they explored ideas like "ambassador programs," embedding experimentation representatives within various product areas to maintain regular contact and stay in tune with their challenges.
Ben noted that this trajectory reflected a common pattern: moving from decentralized units, centralizing, and then evolving into a Center of Excellence (CoE) type of structure.
Does CoE, like at companies such as Spotify or Uber, eventually dissolve as experimentation becomes so deeply embedded in the company's DNA that product teams simply test as a matter of course, relying on standardized tools and processes built by the former CoE?
Liam wasn’t certain Booking.com had reached that stage. He still saw value in a centralized group overseeing the broader picture, particularly concerning data infrastructure and developing scalable statistical methods.
However, he acknowledged a key drawback of centralization: the central team could become a "roadblock" because different product teams often have diverse needs, leading to less agility.
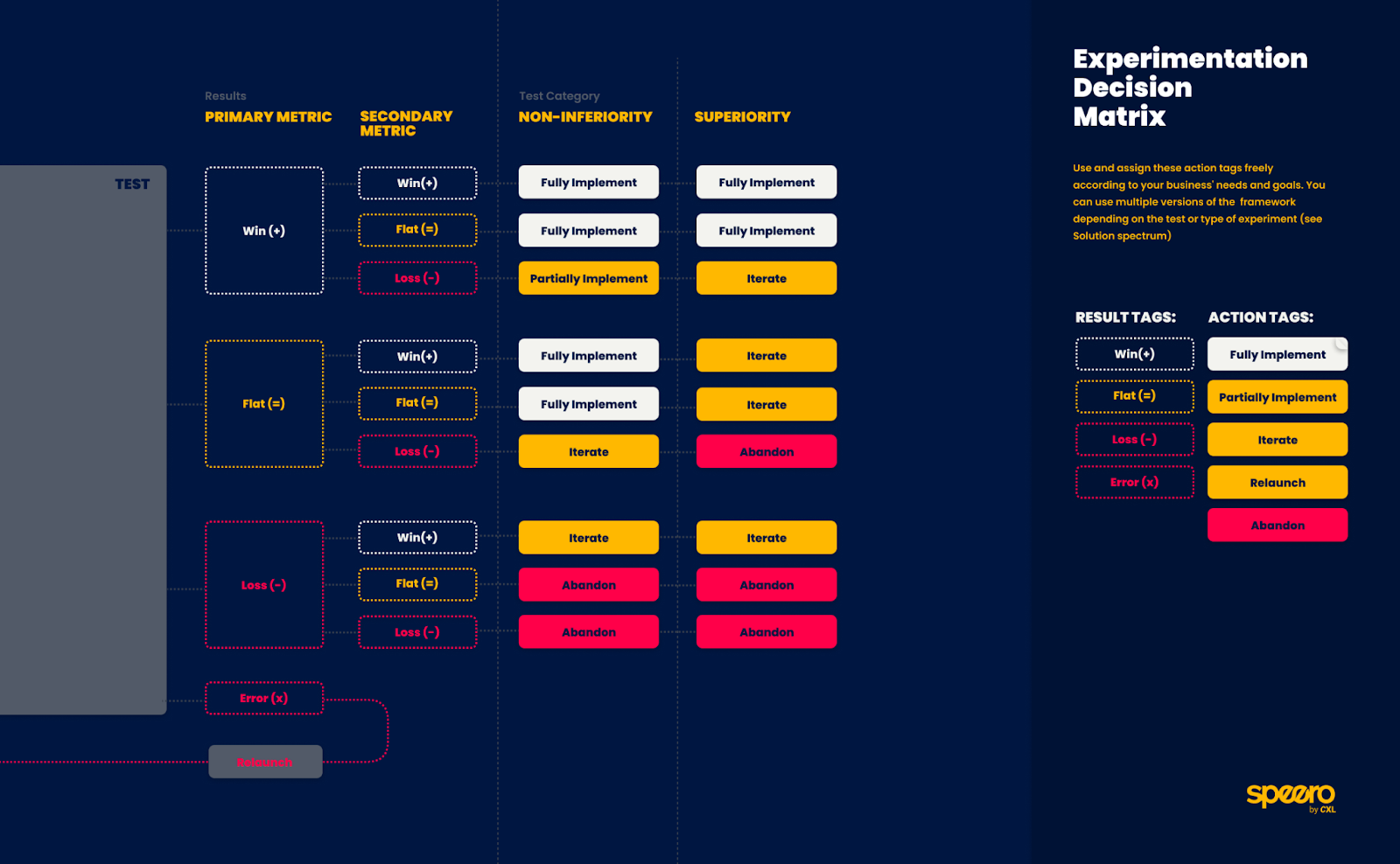
A good blueprint to mention here is the Experimentation Decision Matrix blueprint. It lets you focus your experimentation efforts toward the actual changes and actions you want to make.
Based on your primary and secondary KPI, what’s going to be your action after you complete the test? This framework will give you a reference on how to tag and classify your results depending on the type of hypo (superiority vs non-inferiority) and the action you take after.
How Incentives Impact High-quality Experimentation
At Meta, the incentive structure was directly tied to revenue goals. To count any progress toward a quarterly revenue goal, a team had to run a backtest. The point estimates from that backtest would be the only figures counted towards their goal. “So if they got a 1-point increase in revenue (in that backtest), that's what they counted.”
The benefit of this system, Liam explained, was that it necessitated strict controls at the final measurement step to ensure the claimed revenue was accurately measured (e.g., no peeking at results early, no running tests shorter than planned).
Once these rigorous controls were in place, teams became highly motivated to run high-quality experiments. They were interested in reliable estimates of impact, and the best way to get those was by running good experiments.
“The teams were saying–I want to set a target of 0 .2 % revenue in Q1. Before the teams even set that target, they already ran 3 experiments to dial in that estimate, because the teams knew they had one shot. Because if your back test gives poor results, you could say goodbye”.
Ben contrasted this with the reality for most organizations– less data and insufficient infrastructure to perform such holdouts or backtests on a quarterly basis. In typical scenarios, testers run a smaller number of experiments per quarter, each with a few weeks of data, and calculate the financial impact for that period.
The problem with such an approach is that without a mechanism to hold teams accountable for test quality, they might "peak," "stop early," or "play the system" to their advantage if they are only managed on metric uplift without a study design component.
Liam mentioned that at Booking.com, they attempted to implement "quality metrics," which tracked standard practices in running experiments. These were reported at the team and department level, and they tried to get senior leadership to buy in and score teams based on them.
Liam felt this was another approach to align incentives, but acknowledged it was significantly harder and prone to loopholes if not consistently monitored. “I just think it's a lot harder and there's probably going to be loopholes.”
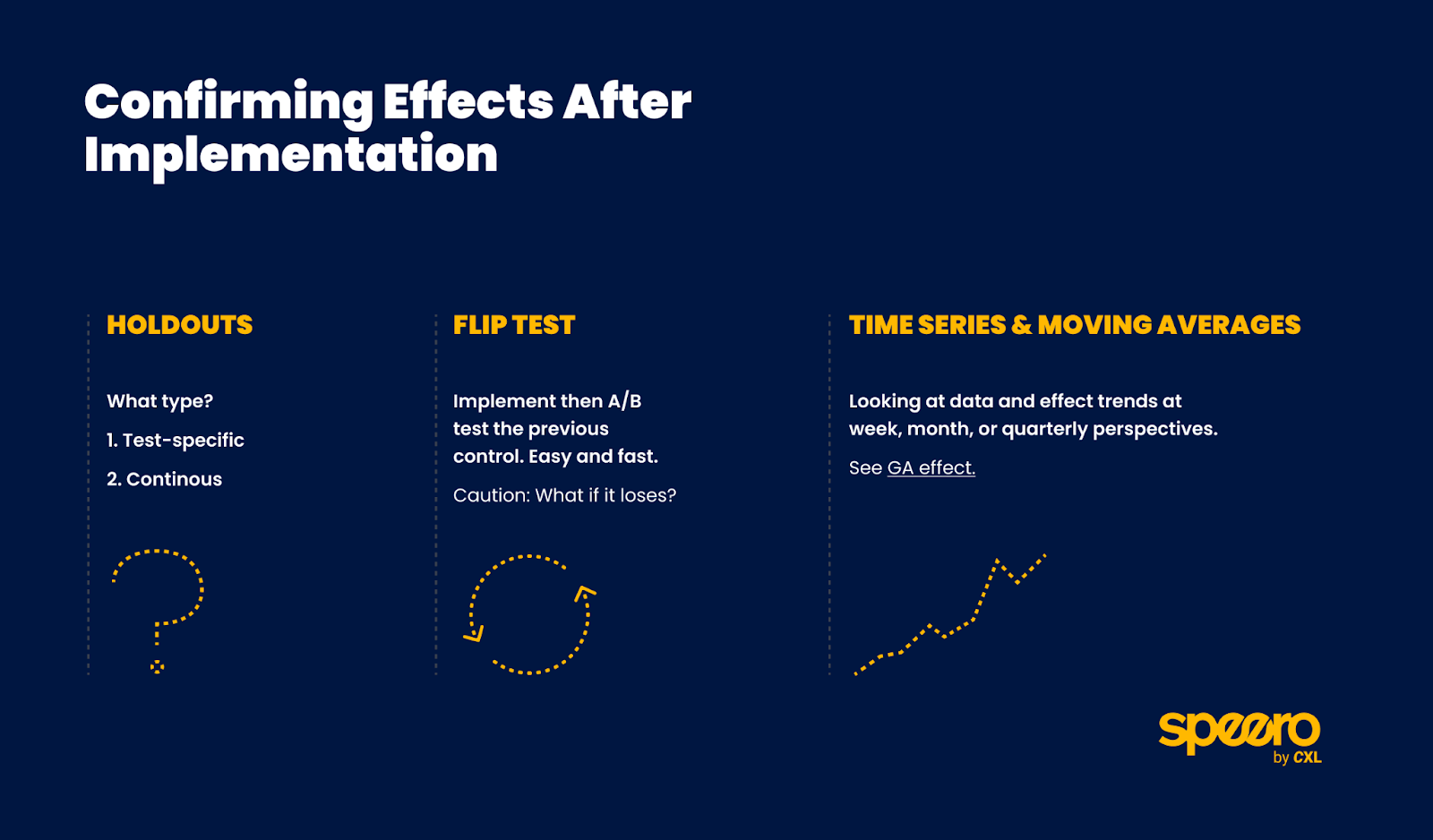
This part wouldn’t be complete if we didn’t mention the 3 Methods for Confirming Test Effects Blueprint. It shows you all three ways to confirm experiment results: holdout groups, flip series, and time series / moving averages.
Getting Buy-In: Proving the Counterfactual
Liam admitted he had been fortunate to work in highly product-driven organizations. However, he theorized that to convince teams to adopt a product operating model, one powerful approach would be to take an idea that people strongly believe in, and then run a test that demonstrates it's actually a bad idea.
He emphasized the concept of the "counterfactual". By showing that "if we hadn't done this [experiment], you would have launched this [bad idea]," it becomes transformative. If a test merely validates an existing opinion, it's not truly impactful. The goal, therefore, is to highlight the value of experimentation by preventing a potentially detrimental decision. This approach can be a powerful way to secure buy-in from leadership.
The conversation ultimately reinforced that building a robust experimentation culture is an ongoing journey. It involves finding the right organizational structure, establishing effective incentives, and consistently demonstrating the value of testing, even when it means revealing what didn't work.






















.svg)
